http://www.asyura2.com/15/hasan100/msg/709.html
| Tweet |
セブンイレブンの強さの源泉?「現場発」ビッグデータ活用…ボトムアップ型の優位性
http://biz-journal.jp/2015/09/post_11660.html
2015.09.21 文=水野誠/明治大学商学部教授 Business Journal
■そもそもビッグデータとは何か?
最近のビジネス関連のニュースで「ビッグデータ」という言葉を見ない日はほとんどありません。しかし、そもそもビッグデータとは何でしょう? ビッグデータに関する多くの記事が、その定義が曖昧であることを認めています(2014年6月9日付 ITmediaビジネス記事『そもそも、ビッグデータって何なの?』http://bizmakoto.jp/makoto/articles/1406/09/news016.html)。
・
以前、コンピュータ科学の研究者にビッグデータの定義について質問したところ、「それはExcelで全部を開けないデータのことです」と冗談めかした答えをいただきました。もちろん、パソコンのExcelで開けるデータの規模は、昔に比べて格段に大きくなっています。つまり、データの規模だけからビッグデータを定義することには限界があるといえそうです。
マーケティングの観点からは、特定の企業や事業分野を超えて収集され、販売(購買)だけでなく流通、広告など関連する諸情報をカバーしたデータ、といった定義が考えられます。たとえば、TポイントやPontaカードから収集されるデータでは、コンビニエンスストアでの購買、レストランでの飲食、ビデオのレンタルなどさまざまな分野の購買履歴がリンク可能です。それにウェブの閲覧履歴や位置情報が加わると、購買の原因となる情報も入手できます。
こうした事実は広く知られていますが、今回考えてみたいのは、そうしたビッグデータの解析についてです。ビッグデータで重要なのは、単にデータの規模が大きいだけでなく、さまざまな質のデータがリンクされていることです。したがって、データの前処理が非常に大変になるわけです。さらに、その解析が従来のマーケティングデータ解析の延長でとらえられないことに注目したいと思います。
結論を先にいえば、筆者はビッグデータが普及するほど、データ解析におけるボトムアップ型のアプローチが重要になると考えています。マーケティングにおけるボトムアップ型発想とトップダウン型発想については、前回の本連載記事で説明しています(http://biz-journal.jp/2015/08/post_11128.html)。この枠組みからビッグデータの利用について眺めると、どんな風景が見えてくるでしょうか。
・
■トップダウン型発想に立つ統計学
筆者はこの4月から米国で研究生活を送っています。するといつの間にか、筆者のPCでインターネットにアクセスすると「アナリティクス」に関する広告がよく現れるようになりました。いま、米国の多くのビジネススクールが「ビジネス・アナリティクス」とか「マーケティング・アナリティクス」といった名前のコースを開設しています。筆者がそうしたサイトを何度か見るうちに、関連する広告が頻繁に配信されるようになったのでしょう。
アナリティクスと似た意味の言葉に、「データサイエンス」があります。日本ではむしろ、そちらのほうが一般的かもしれません。データサイエンスには学術的な語感がありますが、アナリティクスはむしろ実務的な感じがします。ともかくその基盤になるのは、データベース技術などを除くと、統計学と機械学習(人工知能の分野で発展したデータ解析手法)です。統計学が基盤にある点は、従来のマーケティングデータの解析と同じです。
統計学(特に推測統計学)の基本は、標本から母集団の性質を把握することです。たとえば、ランダムに選ばれた1,000人の標本から、自社製品の購入者が30%いるという調査結果が得られたとします。では、日本の消費者全体(母集団)での購入率はどれくらいになるか? それを明らかにするのが統計的推測です。これは、全体の性質を知って、セグメンテーションやターゲティングに役立てようとする点で、トップダウン型発想にしたがっています(図1を参照)。
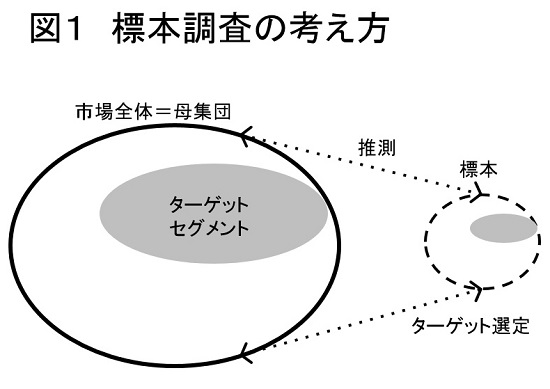
ビッグデータは市場全体を網羅したデータなので、こうしたトップダウン型アプローチがますます進展すると思われるかもしれませんが、筆者はむしろ逆だと考えています。多くのビッグデータは確かに大規模ですが、母集団を代表させるべく集められたデータではありません。その特徴はむしろ細部に関する詳しさにあり、そこで重要になるのは全体ではなく、部分なのです。そのことについて、以下述べていきたいと思います。
■ボトムアップ型アプローチとしてのデータマイニング
ビッグデータとかデータサイエンスとかいう言葉が登場するはるか以前に、「データマイニング」という言葉が普及しました。マイニングとは採掘のことで、データという山に眠る金脈を掘り起こすための手法群です。そのなかで実務家が最も期待した手法のひとつが、マーケットバスケット分析(アソシエーション分析)です。巨大かつ詳細なデータから、同時に起きがちな事象を拾い出してくる手法です。
その「事例」としてよく挙がるのが、平日の夕方に男性が紙おむつとビールを併買する傾向が発見されたというエピソードです。それが事実であったかどうかはともかく、わかりやすい例なので重宝されてきました。この例にもとづいてバスケット分析を簡単に紹介すると、それは図2にある「確信度」と「支持度」の両方を基準に併買パターンを見つける手法だといえます。
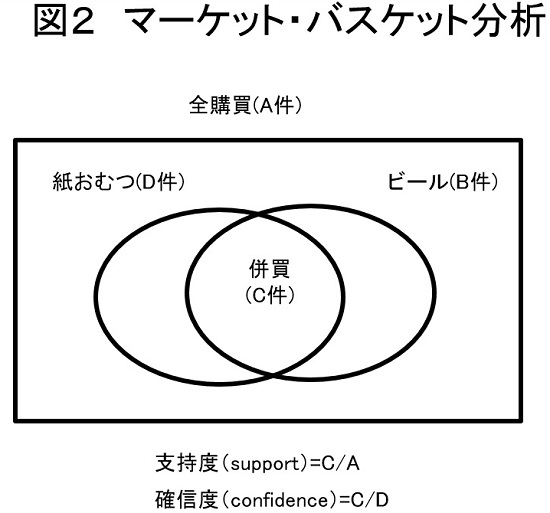
確信度とは紙おむつを買った男性が同時にビールを買う条件付確率で、支持度とはそうした併買が全体の購買のなかで起きる確率です。確信度が高いと紙おむつを買った男性にビールも買わせるプロモーションが成功しそうですが、支持度が一定の水準にないと、併買が促進されてもたいした売り上げになりません。したがって、一定の支持度を満たす範囲で、確信度がより高い併買パターンに注目することになります。
では、支持度はどれくらいあればいいのでしょうか。
これは、まさに経営者の意思の問題といえるでしょう。個別のプロモーションではそれほど大きな売り上げが得られなくても、それらをこまめに繰り返していけば、全体としての売り上げを着実に積み上げることができるかもしれません。部分に潜むチャンスを見つけて販売努力を積み重ねることは、まさにボトムアップ型アプローチといえるものです。
もうひとつの問題は、上述のような併買傾向が、機械的な計算だけから現実的な時間内に発見されるかどうかです。品目の数は膨大で、顧客特性や時間帯まで考えると検討すべき組み合わせの数は天文学的数字になります。しかし、現場のマネージャーの気づきをデータで検証したという話なら、もっと現実的です。『鈴木敏文の「統計心理学」』(勝見明/日経ビジネス人文庫)によれば、セブン-イレブンではそれが実践されているようです。
つまり、ビッグデータからマイニングを行う場合、現場での気づきとか、特定の製品へのこだわりとか、与えられた「場所」から出発して局所的に探索するほうが現実的だということです。計算上も探索の初期状態が固定され、分析範囲に制約があるほうが効率的になります。部分を掘り下げることで得た知識を積み重ね、範囲を周囲に拡大していくボトムアップ型アプローチは、ビッグデータ時代だからこそ基本になると筆者は考えます。
なお、今回の問題についてもっと詳しく知りたい方は、「組織科学」(白桃書房/6月号)に掲載された拙稿『マーケターが見るビッグデータの夢はかなうか?―トップダウン発想 vs. ボトムアップ発想という視点―』(http://www.amazon.co.jp/dp/B00ZJ060SC)をご覧ください。
・
(文=水野誠/明治大学商学部教授)
|
|
|
|
投稿コメント全ログ コメント即時配信 スレ建て依頼 削除コメント確認方法
▲上へ ★阿修羅♪ > 経世済民100掲示板 次へ 前へ
|
|
 スパムメールの中から見つけ出すためにメールのタイトルには必ず「阿修羅さんへ」と記述してください。
スパムメールの中から見つけ出すためにメールのタイトルには必ず「阿修羅さんへ」と記述してください。すべてのページの引用、転載、リンクを許可します。確認メールは不要です。引用元リンクを表示してください。